|
|
|
Este trabalho apresenta um Ambiente para Composição Inteligente de Documentos (CID). Esse ambiente compõe documentos a partir de documentos primitivos armazenados em uma biblioteca, usando técnicas de recuperação de informações para lidar com os perfis dos documentos.
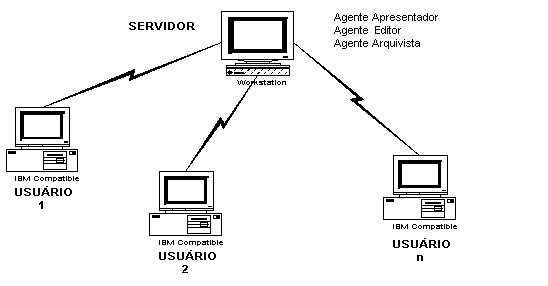
Esse ambiente é composto de três agentes (Editor, Arquivista e Apresentador), distribuídos geograficamente em redes que suportem a World Web Wide (WWW).
Esse ambiente pode ser usado para a composição de documentos didáticos, respeitando as particularidades do aprendiz.
Palavras-chave: Recuperação de Informação, Agente Inteligente, Arquitetura multi-agente, Documento Inteligente.
This work shows an Environment for Intelligent Document Composition (IDC). This environment make documents from primitive documents in a library, using information retrieval technics to deal with the documents "perfis" .
This environment is composed by tree agents ("Editor", "Arquivista", and "Apresentador" ), geographically distributed in the World Wide Web.
This environment can be used to make didactic documents, with respect to the learner.
Keywords: Information retrieval, Intelligent Agent, Multi-agent Architecture, Intelligent Document.
O acesso a recursos da INTERNET, tal como a Web (WWW), principalmente por usuários inexperientes, demanda interfaces amigáveis e sistemas efetivos para pesquisar texto. Esses dois eventos têm contribuído para acelerar as pesquisas sobre metodologias e ferramentas para tratamento de informações, incluindo um maior uso de técnicas para processamento de linguagem natural [Girardi93].
Com a massificação dos computadores tornou-se possível ter acesso a enormes quantidades de informações, tais como, enciclopédias, documentos de pesquisas, de desenvolvimento, etc. Isto tudo passou a ser feito através do uso do computador e da Internet, sendo que essas informações podem ser alteradas e atualizadas a qualquer momento.
Um documento ficou permanentemente flexível, sempre pronto para que seja mudado.
A recente proliferação de computadores e redes de comunicação têm tornado possível acessar uma grande variedade de fontes de informação na Internet. Entretanto, o uso efetivo dessas fontes de informação (ex., documentos, artigos, mensagens de correspondência eletrônicas, notícias, etc.) requer ferramentas sofisticadas para localizar, classificar, e recuperar somente aqueles itens que são de interesse para o usuário.
Também tem surgido uma nova classe de sistemas distribuídos,
os sistemas multi-agentes, onde componentes de software (agentes), distribuídos
geograficamente em uma rede, interagem para resolver problemas, usando
a metáfora de uma equipe de trabalho composta por especialistas
de diversas áreas.
Os documentos são informações organizadas e estão sempre presentes para melhorar a compreensão humana
Os novos documentos já usam imagem e som como conteúdo
de formas não lineares (hipermídia). Também têm
surgido novas tecnologias para processar, analisar e interpretar o conteúdo
[Ronald96].
Os documentos primitivos podem ser documentos selecionados pelo professor ou pelo aluno. Um desses documentos pode ser um capítulo de livro ou de apostila, notas de aula, uma aula gravada ou filmada, mapas, figuras, etc. Quando o documento não for texto, o sistema solicita um resumo em forma de texto que descreva o seu conteúdo.
No CID, a inserção de um novo documento na biblioteca de primitivos é simples, bastando informar o documento. O próprio sistema construirá o perfil do documento, usado para recuperar documentos da biblioteca (BDP).
Os documentos da biblioteca (BID) serão organizados por áreas de conhecimento. Cada área de conhecimento é estruturada por tópicos. Essa estrutura é usada para organizar a seqüência dos documentos primitivos no documento final.
A recuperação de documentos tem sido assunto de estudo por várias décadas [Salton83]. Entretanto, pesquisas que usem sistemas multi-agentes para a recuperação de documento são raras. Alguns exemplos incluem WebWatcher [Joachims et al.97] , WebWatcher Pessoal [Mladenic96] , Fab [Balabanovic97; Balabanovic e Shoham97] que aprendem quais os interesses e desejos do usuário, observando o próprio usuário, chegando a pesquisar e recomendar páginas Web de preferência do usuário. Também existem os agentes de software para correspondência, onde as notícias eletrônicas são tratadas com o uso de filtros [Maes97] .
Um sistema multi-agente que usa recuperação de informação é o Qsabe [Pessoa97] que a partir dos perfis de perguntas e respostas mais freqüentes (FAQ), apresenta respostas a perguntas, feitas por e-mail, recuperando-as de um FAQ.
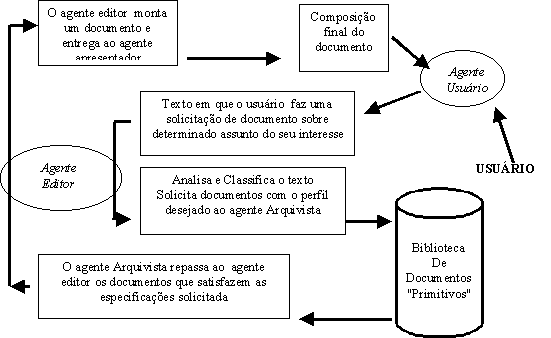
A arquitetura do sistema CID, apresentada nas figuras 1 e 2, mostra os vários agentes que cooperam para realizar a tarefa de compor documentos, especificados pelo usuário, a partir dos documentos primitivos.
O perfil do documento será composto por palavras-chave e as respectivas freqüências no documento.
Com o perfil, o Editor solicita ao agente Arquivista que recupere os documentos primitivos relacionados ao perfil. (Figura 4)
O Editor conhece a estrutura de cada área de conhecimento, com a correta sequenciação dos tópicos, considerando os pré-requisitos de cada tópico. O Editor usa essa estrutura para organizar os documentos primitivos no documento final.
Outro papel do Editor é tratar os documentos primitivos que serão incorporados à biblioteca de documentos. Nesse papel, ao receber um documento, ele fará uma análise para encontrar o perfil desse documento. Essa análise é semelhante a relatada para capturar o perfil da especificação do usuário. Após isso, encaminha ao Arquivista o documento primitivo com o seu perfil.
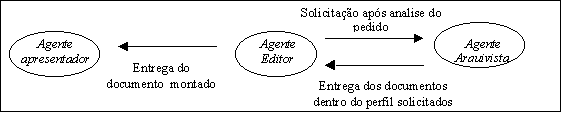
O Arquivista recorre à sua biblioteca de documentos primitivos e separa os documentos relativos ao pedido, que satisfaçam o perfil da especificação feita pelo usuário.
Finalmente, ele devolve ao Editor os documento(s) com o perfil desejado.
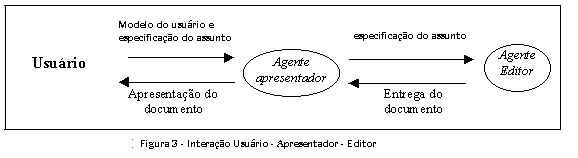
A figura 5 apresenta como ocorre a interação entre o agente Editor e o agente Arquivista.

O usuário deve escolher um assunto e descrever uma especificação do documento pretendido.

O Editor solicita ao Agente Arquivista que localize em sua base de conhecimento os perfis dos documentos primitivos mais próximos. A seguir, o Arquivista envia ao Editor o endereço dos documentos primitivos. Então, o Editor os organiza, montando o documento final, usando a seqüência do tópicos da estrutura do domínio de conhecimento e o perfil do usuário.
Quando o Arquivista recuperar mais de um documento primitivos com perfis semelhantes, o Editor selecionará o de perfil mais próximo da especificação, ou seja, aquele de maior peso (pontuação), conforme mostra o exemplo a seguir:
Dado que o Arquivista devolva 3 perfis com as seguintes características:

O CID pretende dar condição ao aprendiz de compor um hiper-documento, sob medida, sobre assuntos que lhe interessem.
Uma das aplicações do CID dentro da educação seria uma biblioteca virtual, com todo o conteúdo de um determinado curso, onde o aluno pudesse consultar e gerar documentos (apostilas) sobre os assuntos que desejar.
Os principais objetivos do CID na Educação são:
Assim, a partir de uma biblioteca de documentos primitivos para cada área de conhecimento, os agentes são capazes de compor documentos encomendados pelos usuários.
Os documentos finais são avaliados pelos usuários e essa avaliação é usada, pelo especialista na área , para ajustar a base de conhecimento do agente que gera os perfis dos documentos primitivos.
O CID pode gerar documentos de qualquer área de conhecimento, basta que exista a biblioteca de documentos primitivos correspondentes.
O uso do ambiente CID para fins educacionais abre perspectivas interessantes e inovadoras que permitem aos aprendizes "confeccionarem" material didático sob medida, escolhendo os autores de suas preferências. Além disso, podem acessar várias visões do mesmo assunto, podendo comparar estilos de abordagem e exposição dos assuntos contidos nos documentos primitivos.
Outra vantagem do CID é a possibilidade do aprendiz acessá-lo de sua casa, via Web, eliminando a necessidade de ir a uma biblioteca ou livraria para obter um texto sobre um determinado assunto. Além disso, documentos primitivos, selecionados ou preparados pelo próprio aprendiz, podem ser catalogados na biblioteca do sistema, ficando disponíveis para uso futuro.
Escolas que oferecem cursos a distância podem usar o CID para dispor a seus alunos textos didáticos, especificados pelo próprio aluno.
A última versão do ambiente CID foi implementada em uma plataforma Delphi. O ambiente Delphi foi escolhido por causa da facilidade de ferramentas para uso em rede, facilitando assim em muito seu uso na WEB.
Referências Bibliográficas
[Pessoa97] J. M. Pessoa. Desenvolvimento Orientado a Agentes: Uma Experiência com Agentes de Interface. Dissertação de Mestrado, Universidade Federal do Espírito Santo, 1997.
[Balabanovic and Shoham97] M. Balabanovic and Y. Shoham. Combining contentbased and collaborative recommendation. Communications of the ACM, March 1997.
[Balabanovic97] M. Balabanovic. An adaptive web page recommendation service. In Proceedings of the First International Conference on Autonomous Agents, 1997.
[Joachims et al.97] T. Joachims, D. Freitag, and T. Mitchell. Webwatcher: A tour guide for the world wide web. In International Joint Conference on Artificial Intelligence, 1997.
[Maes97] P. Maes. Agents that reduce work and information overload. In J. Bradshaw, editor, Software Agents. MIT Press, Cambridge, MA, 1997.
[Ronald96] Ronald A. Cole, Joseph Mariani, Hans Uszkoreit, Annie Zaenen and Victor Zue - Survey of the State of the Art in Human Language Technology (1996) - Center for Spoken Language Understanding, Oregon Graduate Institute, USA University of Pisa, Italy
[Salton83] Salton, Gerard. McGill, Michael. Introduction to Modern Information Retrieval. Editora McGraw-Hill, New-York, 1983
[Finin94] Finin, T., Fritzson, R., McKay, D., McEntire, R., "KQML as na Agent Communication Language", Proceedings of the Third International Conference on Information and Knowledge Management, 1994.